Reinforcement Learning
There are three basic types of learning: supervised, unsupervised and Reinforcement Learning (RL). RL learns from rewards that are received from the environment. Well known type of model-free RL is called Q-Learning, which does not require model of the problem before-head. The agent controlled by the Q-Learning algorithm is able to learn solely by:
- observing states
- producing actions
- observing new states and rewards.
The RL algorithm learns how to obtain the reward and while avoiding the punishment (negative reward). The Q-Learning is named after the Q function, which computes Quantity of state-action combination: $\mathbf{Q} : \mathbf{S} \times \mathbf{A} \rightarrow \mathbb{R}$, where $\mathbf{S}$ is set of states and $\mathbf{A}$ set of actions. For each state, the $\mathbf{Q}(s_i,a_j)$ tells the system how good particular actions $a_j \in \mathbf{A}$ are.
In the discrete case, the system operates in discrete time-steps and the $\mathbf{Q}$-values are stored directly in the look-up table/matrix. The system learns iteratively towards the optimal strategy by updating the following equation:
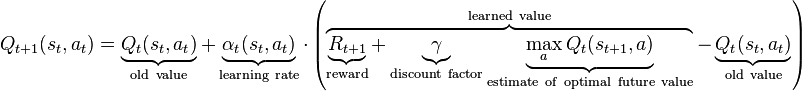
At each time step, the agent:
- selects the action $a_t$ at the current state $s_t$ (by using the Action Selection Method (ASM))
- executes the action $a_t$
- observes new state $s_{t+1}$
- receives the reward $R_{t+1}$
- finds the utility of the best action in the new state: $\underset{a}{max} Q_t(s_{t+1},a)$
- updates the $\mathbf{Q}(s_t,a_t)$ value according to the equation above.
We can see that the equation spreads the reward one step back. The learning is configured by parameters $\alpha$ (learning rate) and $\gamma$ (how strongly is the reward spread back ~ how far in the future agent sees).
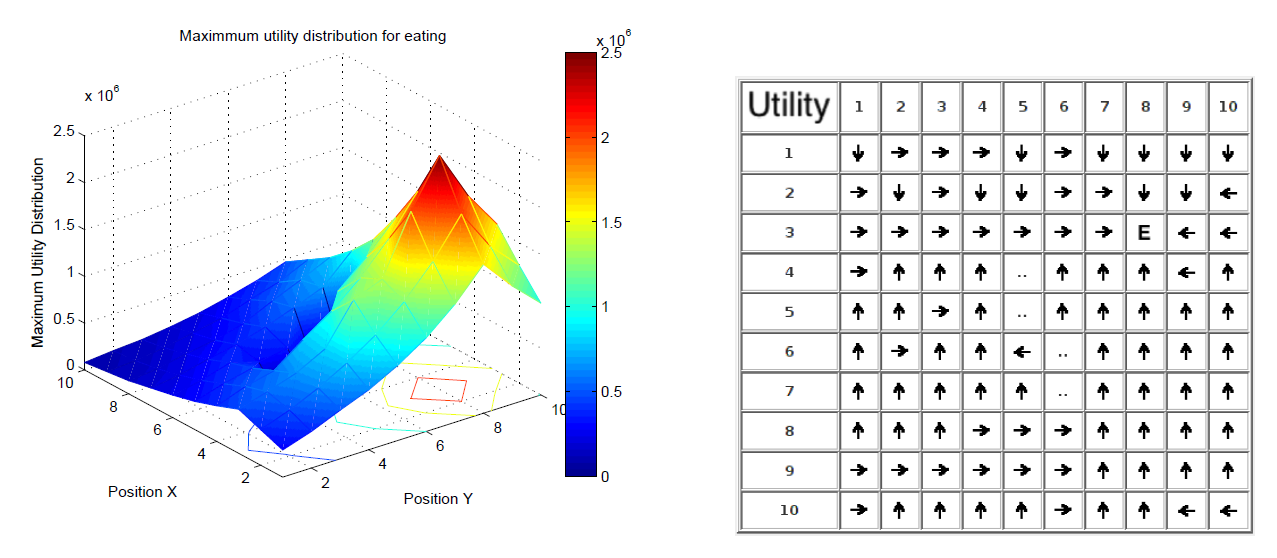
The following figure shows an illustration of learned strategy by the Q-Learning algorithm (actions: $\mathbf{A} = \lbrace Left, Right, Down, Up, Eat \rbrace$ , positions: $\mathbf{S}= \lbrace x,y \rbrace$). On the right there is a best action at each position, on the left side there is utility value of the best action in the position. Agent receives the reward it it executes action Eat at a given position. The nearer the reward, the higher the action utilities are.
Our discrete Q-Learning Node uses also Eligibility trace, which enables the system to update multiple $\mathbf{Q}$-values at one time-step. This improvement is often called $\mathbf{Q(\lambda)}$ and greatly speeds-up learning. The parameter $\lambda$ defines how strongly is current difference projected back. The higher the parameter, the faster the learning. But too high value can destabilize the learning convergence.
Discrete Q-Learning Node
The $\mathbf{Q(\lambda)}$ algorithm is implemented in the DiscreteQLearningNode. It receives state description, reward(s) and action that has been selected for execution. It publishes vector of utility values of all actions in the given state. Furthermore, these values are multiplied by the amount of motivation on the input.
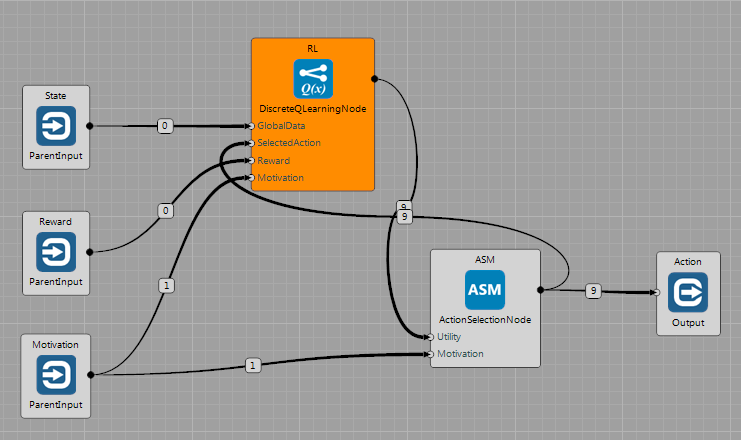
The Node expects positive values on the GlobalData input. If these are not integers, they can be discretized/rescaled in the Node's configuration. The Node updates sizes of particular Q-matrix dimensions on line, based on the input values that are fed into the Node. Therefore the input data can be either variables or constants. For more information, see the documentation of the Node.
When to Use the Node
It is suitable to use this Node if the problem:
- Is discrete: such as
TicTacToeWorldorGridWorld. The discrete Q-Learning will have problems with learning in continuous worlds such asCustomPongWorld. Possible solution is in discretization of the problem (see theInputRescaleSizeparameter). - Has reasonable dimensionality: The Node stores Q-value matrix containing all state-action combinations that have been visited. The matrix is allocated dynamically, but if the agent encounters too many world states (and/or has too many actions) the memory requirements can grow very quickly.
- Fulfills the MDP property: A world fulfilling the Markov Decision Process is such a world, where transition to the next state $s_{t+1}$ depends only on the current state $s_t$ and action taken by the agent $a_t$. That is: "there is no hidden dynamics" in the task. In other words: the environment should be fully (or at least partially) observable.
Examples of use of this Node are here, description how to use it just below
Action Selection Method Node
The DiscreteQLearningNode learns on line by interaction with the environment through own actions. Therefore it has to be able to weight between exploration of new states (searching for rewards) and exploitation of the knowledge. Here we use motivation-based $\epsilon-greedy$ Action Selection Method (ASM). The $\epsilon-greedy$ selects random action with $P=\epsilon$ and the best action (the highest utility) otherwise. The ActionSelectionNode (see above) implements motivation-based $\epsilon-greedy$ method, where $\epsilon = 1-motivation$. This means that: the higher motivation: the less randomization (the more important is to exploit the knowledge).
How to Use the Node
Supposed to be used mainly with the DiscreteQLearningNode or DiscreteHarmNode for selecting actions based on utility values and the motivation. Recommended use case is the following:
- Start learning with small (preferably zero) motivation (the system explores)
- Optionally increase the motivation (system will tend to "wander around reward source(s)" more)
- Use the system (motivation is high ~ knowledge exploitation is high). If the behavior is not sufficient, continue with exploration.
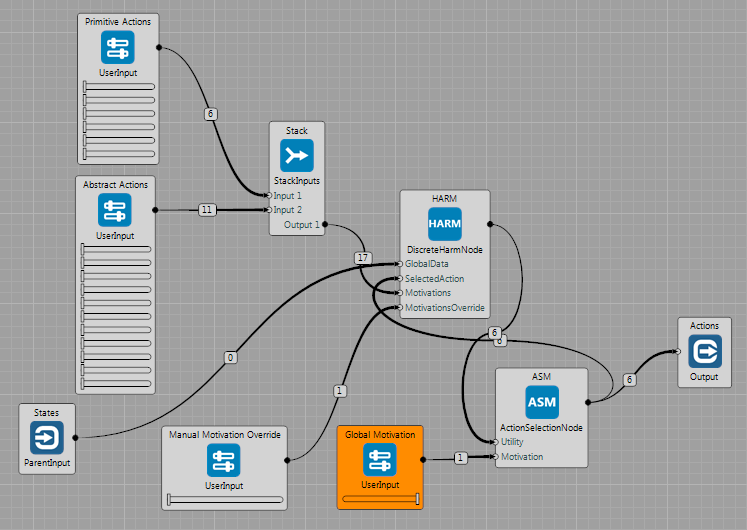
Discrete HARM Node
The DiscreteHarmNode implements algorithm loosely inspired by the Hierarchy Abstractions Reinforcements Motivations architecture. It uses multiple Q-Learning engines/Stochastic Return Predictors (SRPs) for learning. In this implementation, the SRPs are created on line (compared to episodic experiments) and only level of 1 of hierarchy is allowed.
Each SRP is composed of:
- Pointers to part of decision space (subspace - subset of child variables and child actions)
- Q-Learning engine with own memory
- Source of motivation with own dynamics
- Pointer to own source of reward
Similarly to the DiscreteQLearningNode, the operation of the DiscreteHarmNode has two phases that are taken consecutively at each time step:
- Learning: all SRPs learn (update own Q-Values) in parallel
- Generating utilities of primitive actions: for each action, sum utilities produced by all parent SRPs.
The output of the DiscreteHarmNode is vector of utilities for all primitive actions in a given state. Utility of each primitive action is composed of utilities of all parent SRPs. This means that all SRPs vote what to do, and the strength of their vote is given by:
- their current motivation
- current distance from their goal.
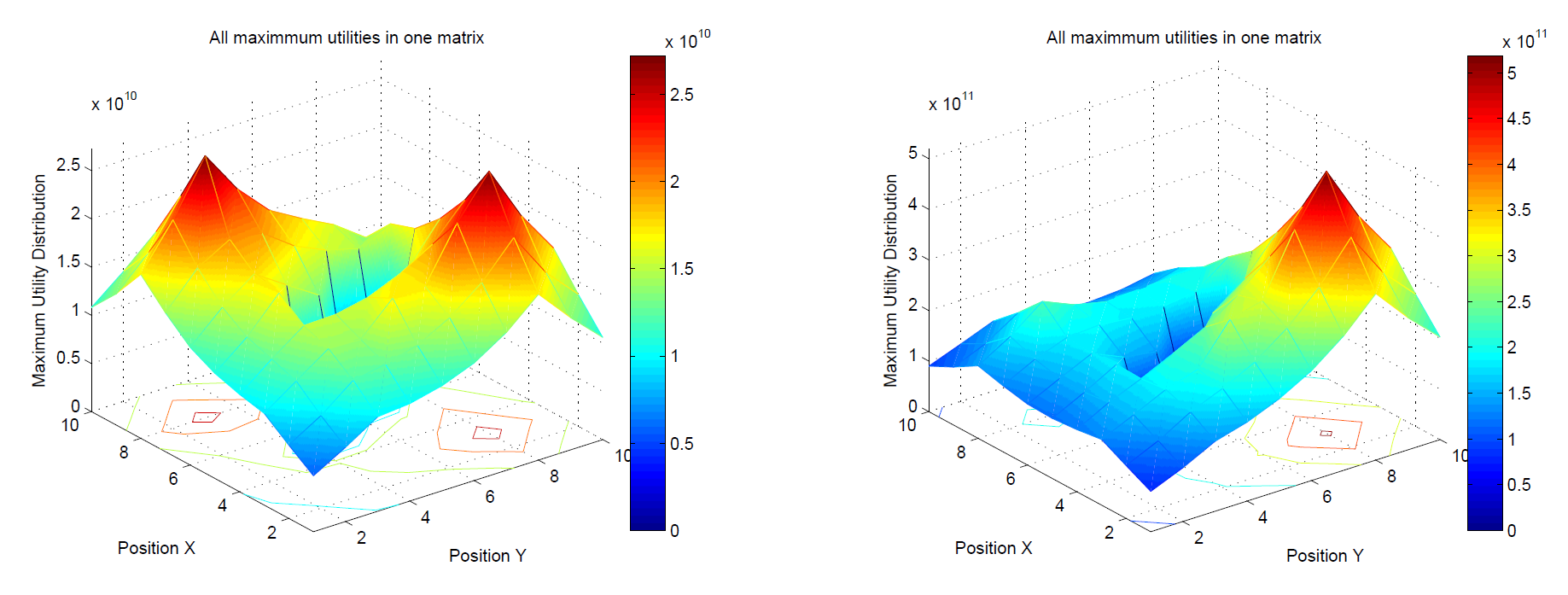
The principle can be seen in the following figure. On the left: composition of strategies from two SRPs with the same motivation. On the right: SRP for the goal on the right has higher motivation (source). This defines what strategy will the agent use based on current motivations and position in the state space.
Main Principle of Work
Here is simplified sequence showing how the architecture works. It starts with no SRPs (and therefore no motivations) at the beginning:
- Compute utilities of primitive actions and publish them
- ASM selects and applies action
- If some new variable changed, do subspacing:
- Create new SRP
- Add only variables that changed often recently
- Add only actions that were used often recently
- Define reward for this SRP as a change of this variable
- Perform variable removing for all SRPs:
- Drop variables that did not change often enough before receiving the reward
- Perform action adding
- If execution of some action has directly to obtaining reward of the SRP, add the action there
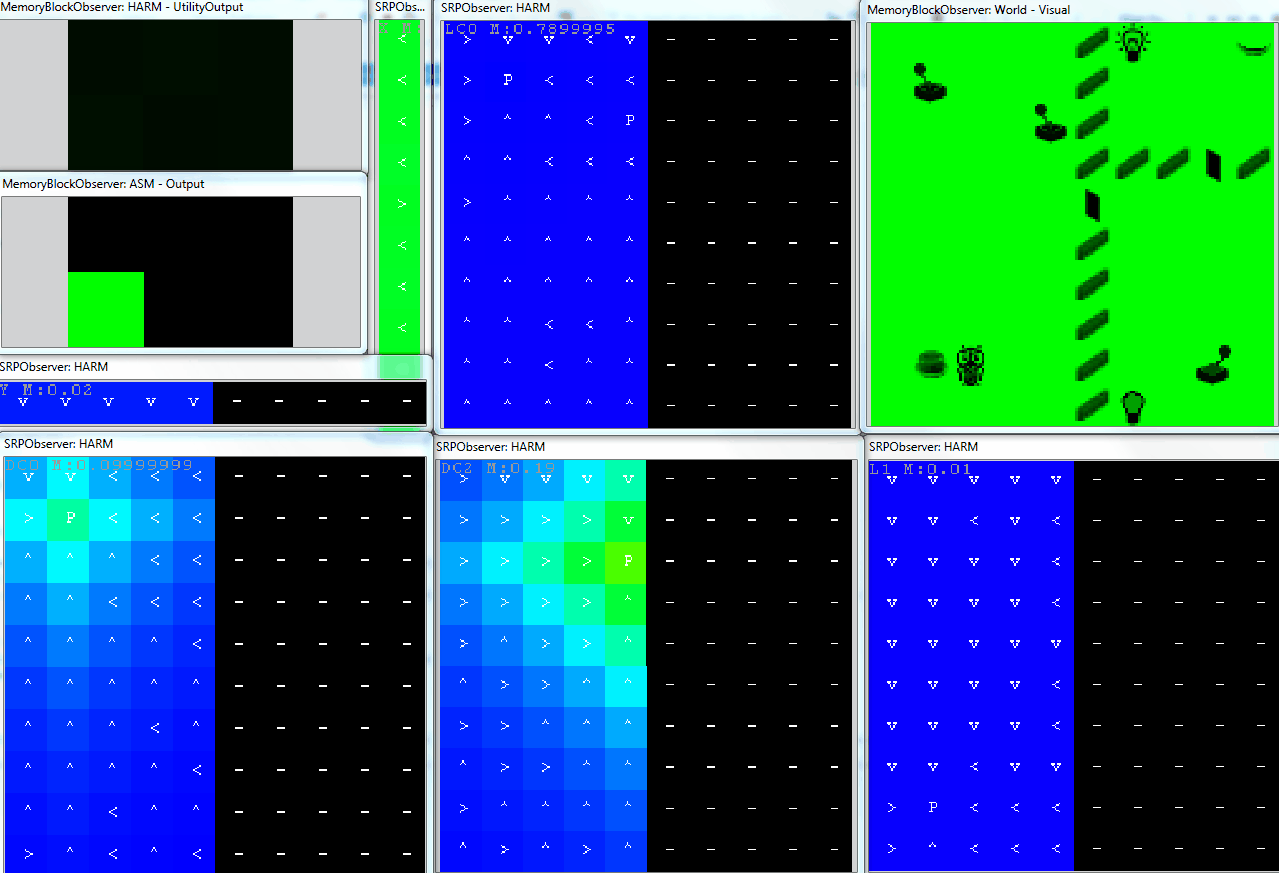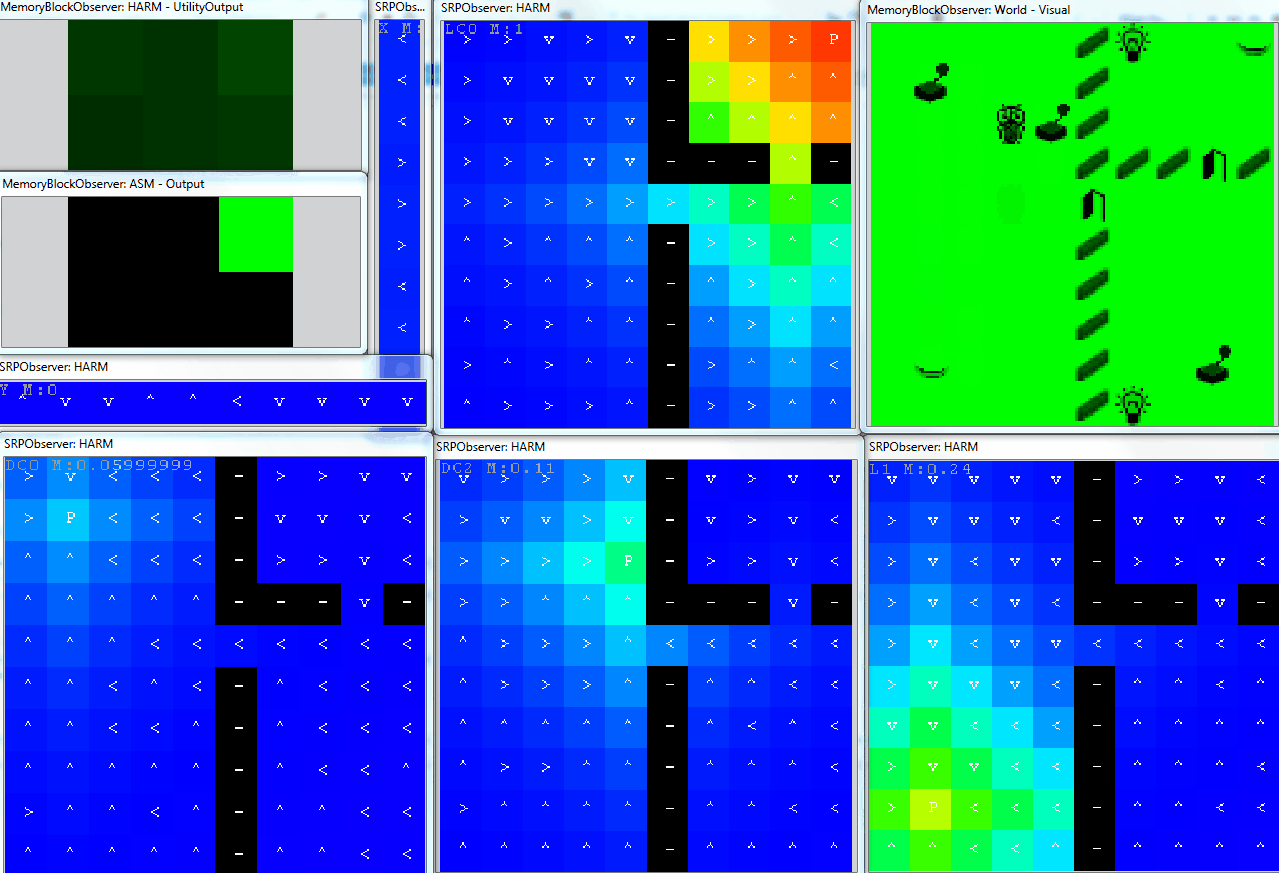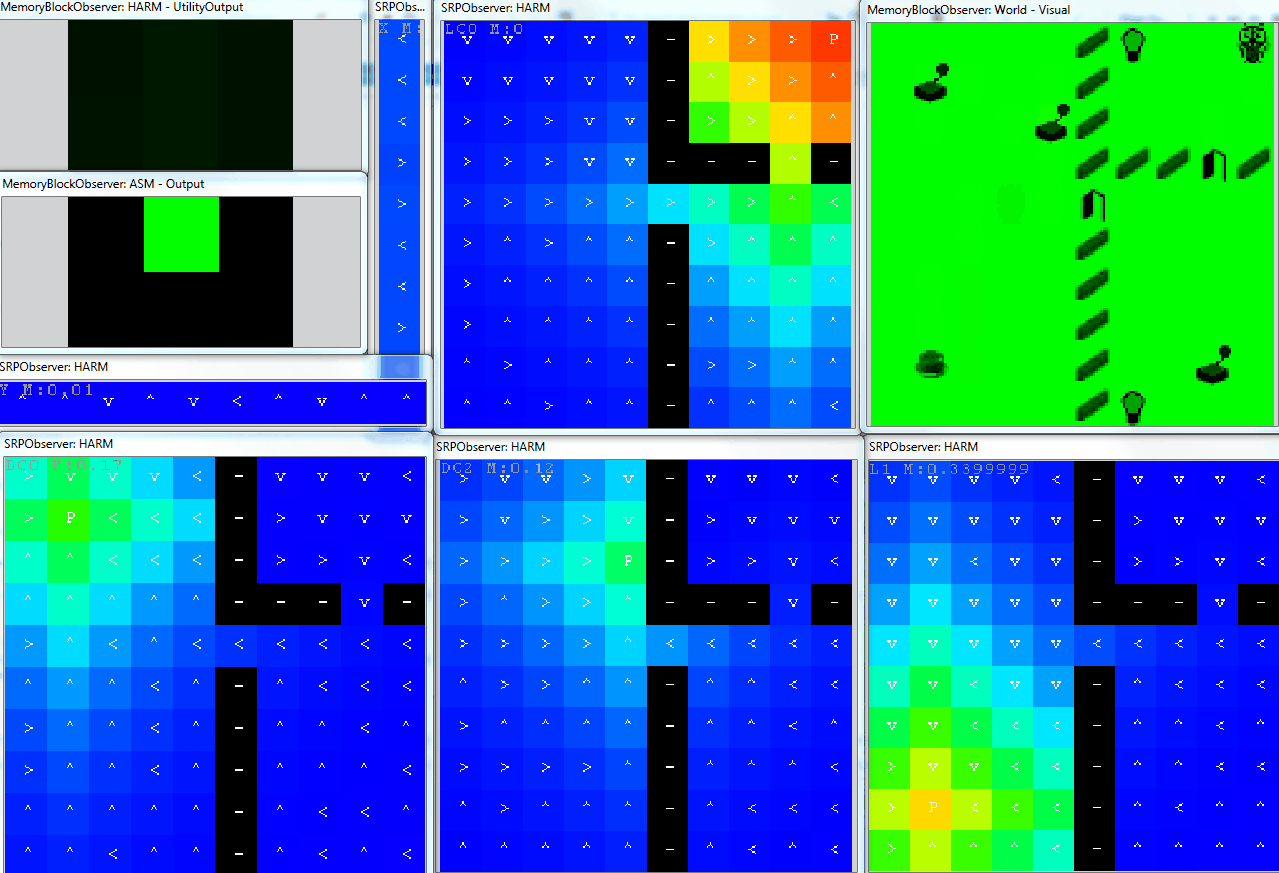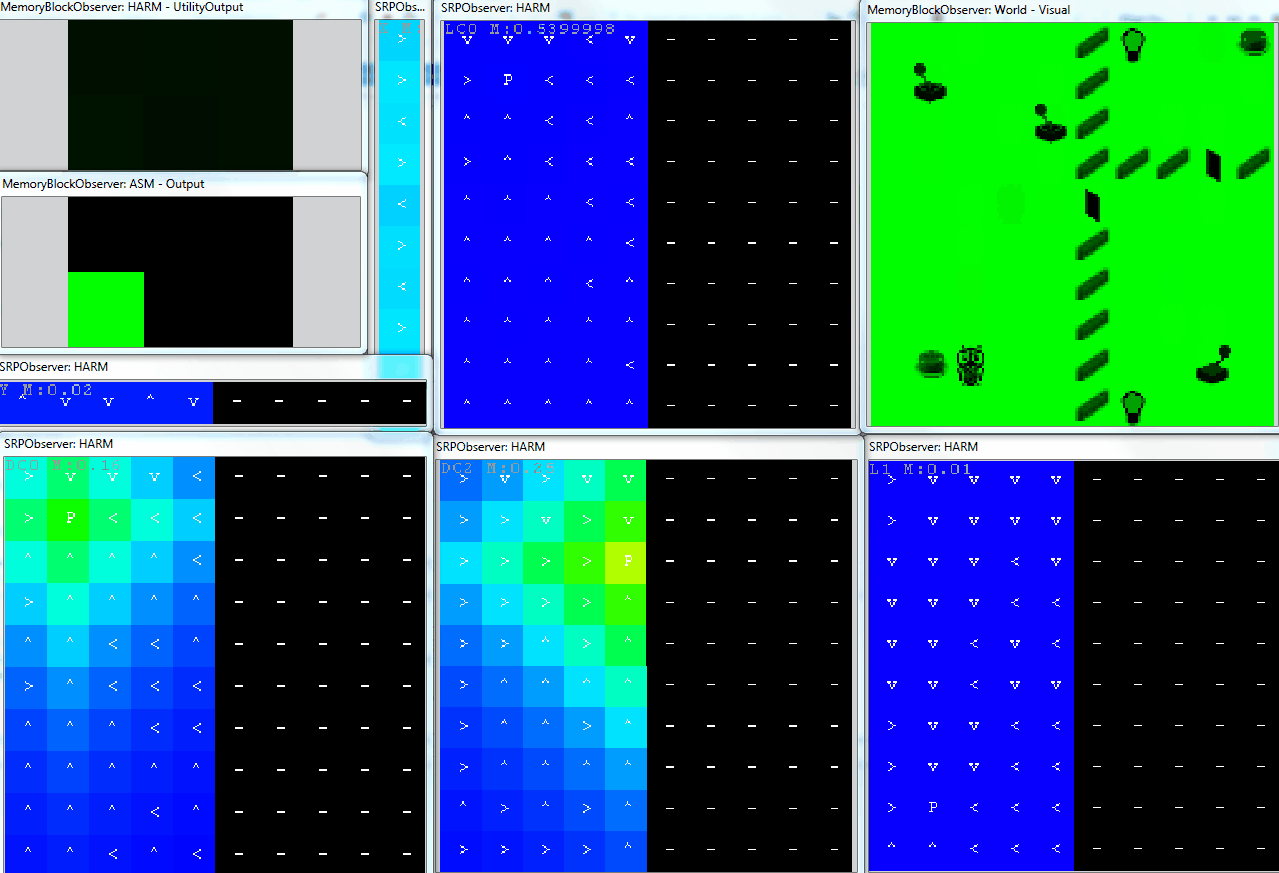
The following animation shows an example of operation of the DiscreteHarmNode in the GridWorld. The agent can do 6 primitive actions ($\mathbf{A} = \lbrace Left,Right,Up,Down,Noop,Press \rbrace)$ and has already discovered 6 own abilities. For each of them it created own decision space, these are:
- move in two directions (X and Y axis - narrow Observers)
- control light 1
- open door 1
- control door 2
- control light 2
On the top left there are current utilities of each primitive action, under it there is the selected action. The corresponding brain is depicted in the figure above. Here, the motivation of ASM is set to 1, so the agent selects actions based on utilities produced by the DiscreteHarmNode. We can see how the agent systematically trains own SRPs based on the dynamics of the motivation sources.
How to Use the Node
In order to use the DiscreteHarmNode, connect state inputs, ActionSelectionNode and two inputs for manual override of inner motivations. If the value of MotivationsOverride input is above 0.5, the SRPs will not use own sources of motivations. Instead, the motivations can be set manually.
Typical use case of the DiscreteHarmNode is as follows:
- Set the
MotivationsOverrideto 0 (own motivations), set theGlobalMotivationof ASM to zero (random actions) - Let the system run to explore the state space and
- create SRPs
- learn different strategies in these SRPs
- Optionally increase the
GlobalMotivationfor focusing nearer to the reward sources - Test the learning convergence by setting the
GlobalMotivationto 1 - If the system is learned well, you can use its capabilities by setting
MotivationsOverride
When to Use the Node
On top of suggestions for use of the DiscreteQLearningNode it needs to be considered that the DiscreteHarmNode learns how to change the environment. So it is best to use it in static environments, where the main changes are caused by the agent's actions.
In case that there is changing variable that is not influenced by the agent, the HARM still assumes that the agent caused the change. It creates SRP which "thinks that it learns the behavior". But the good property of this is that:
- If the independent variable changes often, the corresponding SRP is "successful" often and therefore it has constantly low motivation. This means that does not vote that strongly what to do.
- If the variable does not change often, there is not much rewards generated and average utility values are very low. Therefore the corresponding SRP still does not vote strongly too, even if its motivation is constantly high.
Example brain files with this node are located here.