RBM MNIST example
This is a working example of a simple two-layer RBM (i.e. not a DBN) trained on the full MNIST dataset (60000 images).
Brain file: RBM_MNIST.brain
Make sure you also have the saved state available if you'd like to see the pretrained version.
For introduction to RBMs, see the RBM guide entry first.
Setting parameters
After opening the brain file, double-click the RBM group to see its contents.
When inside the group, you can select its layers. You can also select the whole group without leaving it – click the square button in lower-right corner:
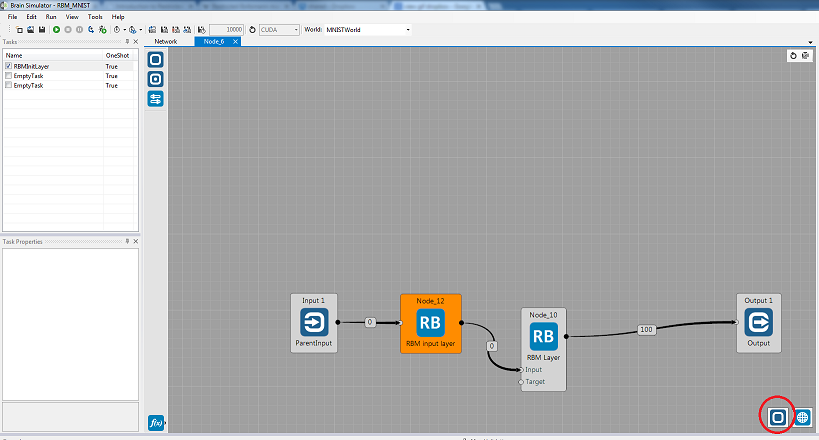
This allows you to access all parameters of group as well as the layers.
Some parameters are layer-specific, such as dropout rate; some are common for the whole group. Refer to the parameter section of the RBM guide for their description and recommendations.
Saving and loading states
You can select whether you'd like to train the RBM from scratch or use the pretrained version by disabling or enabling the load button for both layers (separately):
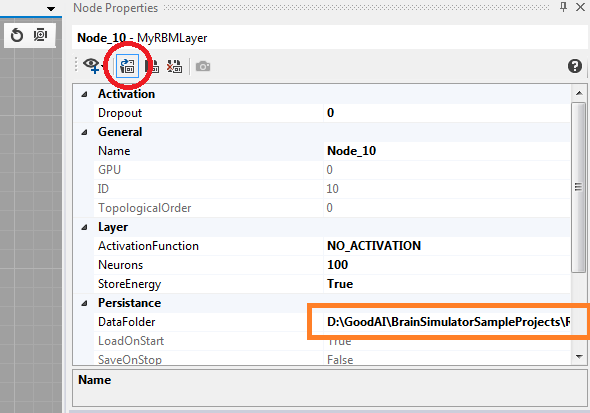
The brain file preserves the location save relatively to its position so the loading should work even if the specified path (orange rectangle in the image above) is not correct for your machine.
Nevertheless, should you want to load a different state file, change the path to the saved memory blocks for each node. See the Persistence guide for details.
Training and generating images
By default, the RBM Learning task is selected in the RBM network group. You can switch to RBM Reconstruction if you'd like to only reconstruct network's input.
When reconstructing, there are two possible ways of using the network.
First is simply reconstructing the input image from the input image (i.e. the network gets an image of number 6 and it bounces it back and forth between its layers a couple of times and reconstructs something hopefully similar to a 6).
The other and arguably more interesting approach is to reconstruct from the hidden layer. To do this, simply change the Reconstruction source of the RBM Reconstruction task to HIDDEN. The layer will then use its Target memory block as a source of activations.
In the example brain file, we use the RandomNode and CSharpNode for first sampling random values and then only keeping about 20% of the values so we get a reasonable amount of activated hidden neurons.
The activations now correspond to activated filters/features of the image and an image will be constructed based on only these hidden features learned previously and activated randomly now.
Play around with parameters such as Iterations, RandomHidden and RandomVisible to get different results of the network's daydreamed numbers.
Keep in mind that when reconstructing from the hidden layer, the input bitmap observer has no relation to the output of the reconstruction (as we are reconstructing from random activations and not from the input).
Visualizing the filters
The process of visualizing the filters while training is underway is one of the biggest advantages of this implementation.
Filters are thoroughly described and explained in the RBM guide.
Below is an example of RBM trained on MNIST for 10 epochs (i.e. 600000 iterations):
